The Q16 Contest is open!
-
@news-quantiacs
 no more futures contests?
no more futures contests? -
@news-quantiacs Great! Looking forward to explore all the cryptos we can trade now.
I just noticed there are a lot of gaps in the prices:
import numpy as np import pandas as pd import qnt.data as qndata data = qndata.cryptodaily_load_data(min_date='2020') close = data.sel(field='close').to_pandas() num_symbols = len(close.columns) nans = np.isnan(close) percent_nans = nans.sum() / len(close) (percent_nans==1).sum() / num_symbols>>> 0.5416666666666666
That means more than half of the symbols have no close prices at all since 2020, do you think you can fix this?
-
@magenta-grimer Hi, not for the moment, maybe in the future. Unfortunately there is no way we can comply with the CME policy. If you have some idea for futures data we can use, please let us know!
-
@antinomy We are including also cryptocurrencies which were liquid in the past according to market capitalization but then they disappeared for various reasons. This is important for avoiding survivorship bias. Did you find assets which are liquid since 2020 and should be present now also?
Imagine to work with stocks which were very popular before the 2008 crash but disappeared later; they would be not present now also.
-
@support
First of all, having looked at various sources for crypto data myself, I know this can be a pain in the neck, so I can appreciate the effort you took to provide it.I get the method for avoiding lookahead-bias by including delisted symbols. The key point would be what you mean exactly by disappeared and from where.
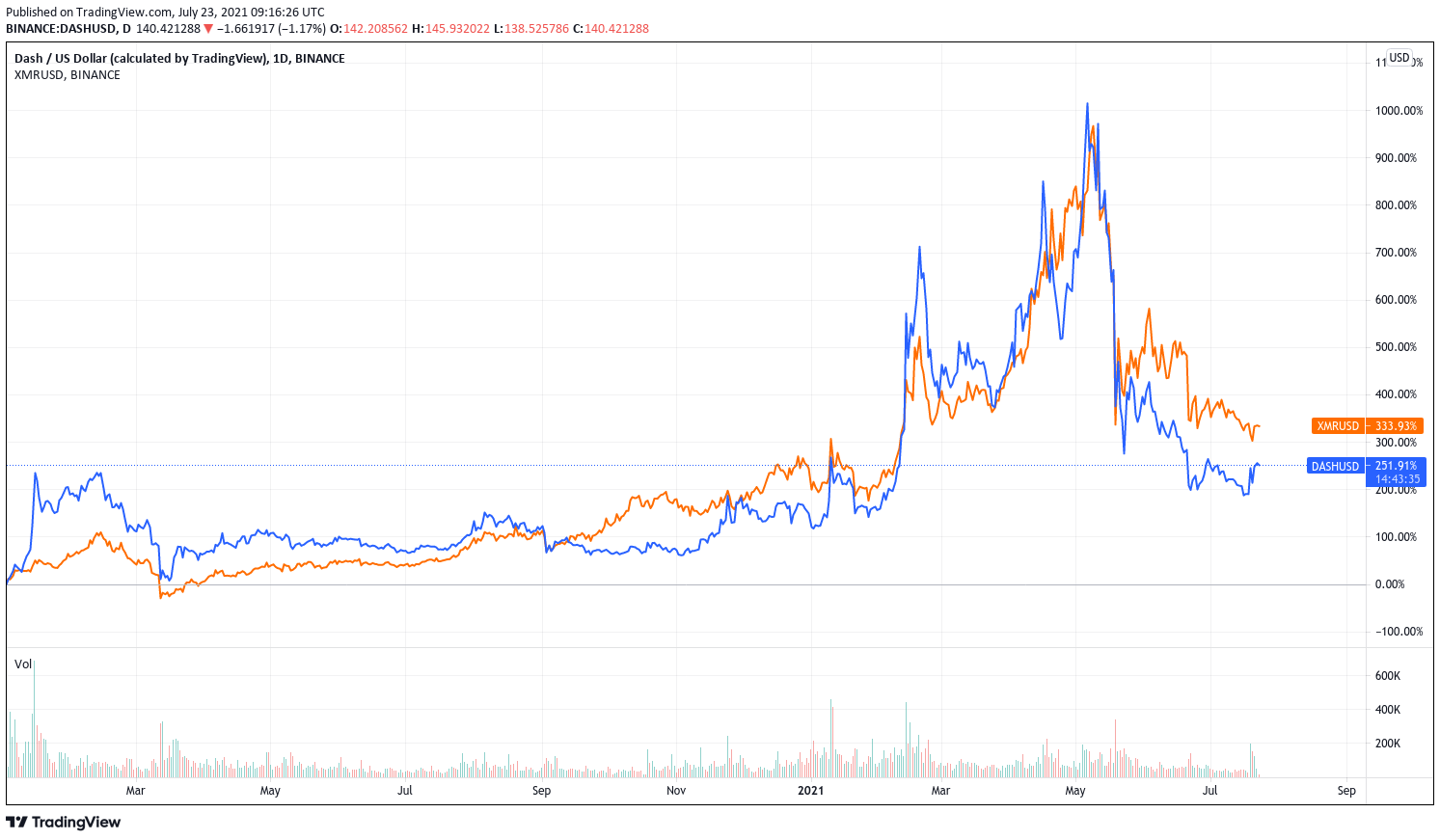
Do you mean they were delisted from the exchange where the winning algos will be traded or did the data source you used just not have data?To name 2 examples: DASH and XMR don't have recent prices but I don't know of an exchange they were delisted from. When I look them up on tradingview they do have prices on all the exchanges available there and are still traded with normal volumes.
Charts for their closing price on quantiacs:
import qnt.data as qndata data = qndata.cryptodaily_load_data(min_date='2020') close = data.sel(field='close').to_pandas() close[['DASH', 'XMR']].plot()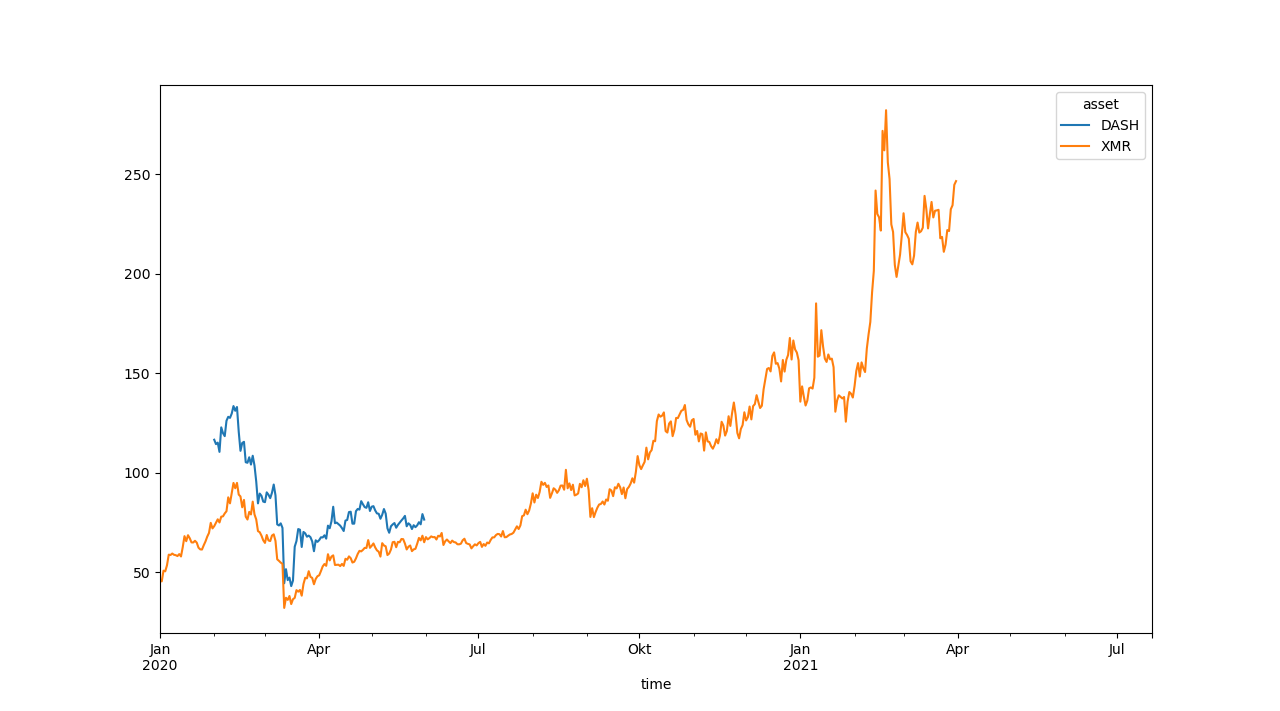
On tradingview:
There are many reasons why we might need prices for symbols that are currently not among the top 10 in terms of market cap. An obvious one would be that they might be included in the filter again any second and algorithms do need historical data. Also, there are many ways to include symbols in computations without trading them: as indicators, to calculate market averages and so on.
-
@antinomy Hello, the criteria we are using is market capitalization according to coinmarketcap data. If at some point a currency was in the top 10 according to their screenshots, the data are included (at least for the period the currency was among the top 10).
Let us suppose DASH will again be in the top 10, on 1 September 2021: then we would include again the data, including the timeslot during which it was not in the top 10.
About using them as filters should be ok however as you say. But it is not trivial: your algorithm should use DASH as indicator, for example, only after it was at some point among the top 10, and not before, otherwise we would incure into survivorship bias, do you agree? There are coins which at some point had a larger market cap than DASH, never made it to top 10, so we never include them...
-
@support
I totally agree that the indicator usage is not trivial at all regarding lookahead-bias, still trying to wrap my head around it")
The symbol list alone could already lead to lookahead bias - in theory, I don't have a realistic example.
Because if the symbol is in the dataset, the algo could know it will be among the top 10 at some point, thus probably go up in price.
I guess we really need to be extra careful avoiding these pitfalls, but they might also become apparent after the submission...From what I understand this contest is kind of a trial run for the stocks contest, so may I make a suggestion?
On Quantopian there was data for around 8000 assets, including non-stocks like ETFs but for the daily contest for instance, the symbols had to be in the subset of liquid stocks they defined (around 2000 I think).The scenarios
- there's a price for that stock, it will become large
- it's included in the asset list, it must go up some day
were not really a problem because there was no way to infer from prices or the symbol being present that it will be included in the filter some day.
Maybe you could do something like that, too?
It doesn't have to be those kind of numbers, but simply providing data for a larger set of assets containing symbols which will never be included in the filter could avoid this problem (plus of course including delisted stocks).For this contest I think your suggestion to retroactively fill the data if a symbol makes it on top again is a good idea.
-
@antinomy Thanks, yes, you are correct, the framework we provide for this contest allows for making submissions which are free from survivorship bias, but is not sufficient to get only submissions which are free from survivorship bias.
A user could for example hard code "trade only BTC and ETH", or use the tricks you suggest at points 1. and 2.
As I understand you suggest to use a "hidden" filter, so the users will have at their disposal many symbols, and we use a filter which is not open to the participants, correct?
Maybe it is ok, but there could be problem when one makes cross-sectional analysis of stocks (well, cryptos in this case).
I imagine that also the initial set of 8k stocks was well defined in some way.
-
@support In my posts I was merely thinking about unintentional lookahead bias because when it comes to the intentional kind, there are lots of ways to do that and I believe you never can make all of them impossible.
But I think that's what the rules are for and the live test is also a good measure to call out intentional or unintentional lookahead bias as well as simple innocent overfitting.To clarify the Quantopian example a bit, I don't think what I described was meant to prevent lookahead bias. The 8000 something symbols just was all what they had and the rules for the tradable universe were publicly available (QTradableStocksUS on archive.org). I just thought, providing data for a larger set than what's actually tradable would make the scenarios I mentioned less likely. For that purpose I think both sets could also be openly defined. Let's say the larger one has the top 100 symbols in terms of market cap, dollar volume or whatever and the tradable ones could be the top 10 out of them with the same measurement.
On the other hand, I still don't know if those scenarios could become a real problem. Because what good does this foreknowledge if you can't trade them yet? And after they're in the top 10 it would be legitimate to use the fact that they just entered, because we would also have known this at that time in real life.
-
@antinomy thank you for the hints, we are thinking and trying to improve setup for the future
-
@antinomy In the end we followed your advise and changed a little bit the algorithm for adding data, once a cryptocurrency is in the top10 we include it with its past history and go on with the update (now DASH and XMR are being updated). Of course once the crypto is not among the top 10, the liquidity tag for the filter is "zero". Thank you!