Machine Learning - LSTM strategy seems to be forward-looking
-
Hi,
Your Machine Learning - LSTM strategy seems to be forward-looking. You train the model using feature_for_learn_df, then you calculate the prediction for features_cur (with timestamp in the past), and then you use the predictions as the weights for those same past timestamps (weights.loc[dict(asset=asset_name, time=features_cur.time.values)] = prediction). In this way you have weights as values from a model that has seen values from the future (from the point of view of the timestamp of the weight).
Thank you -
@black-magmar Hello. Perhaps this seems strange, but not entirely so.
Notice how the target classes are derived — a shift into the future is used.
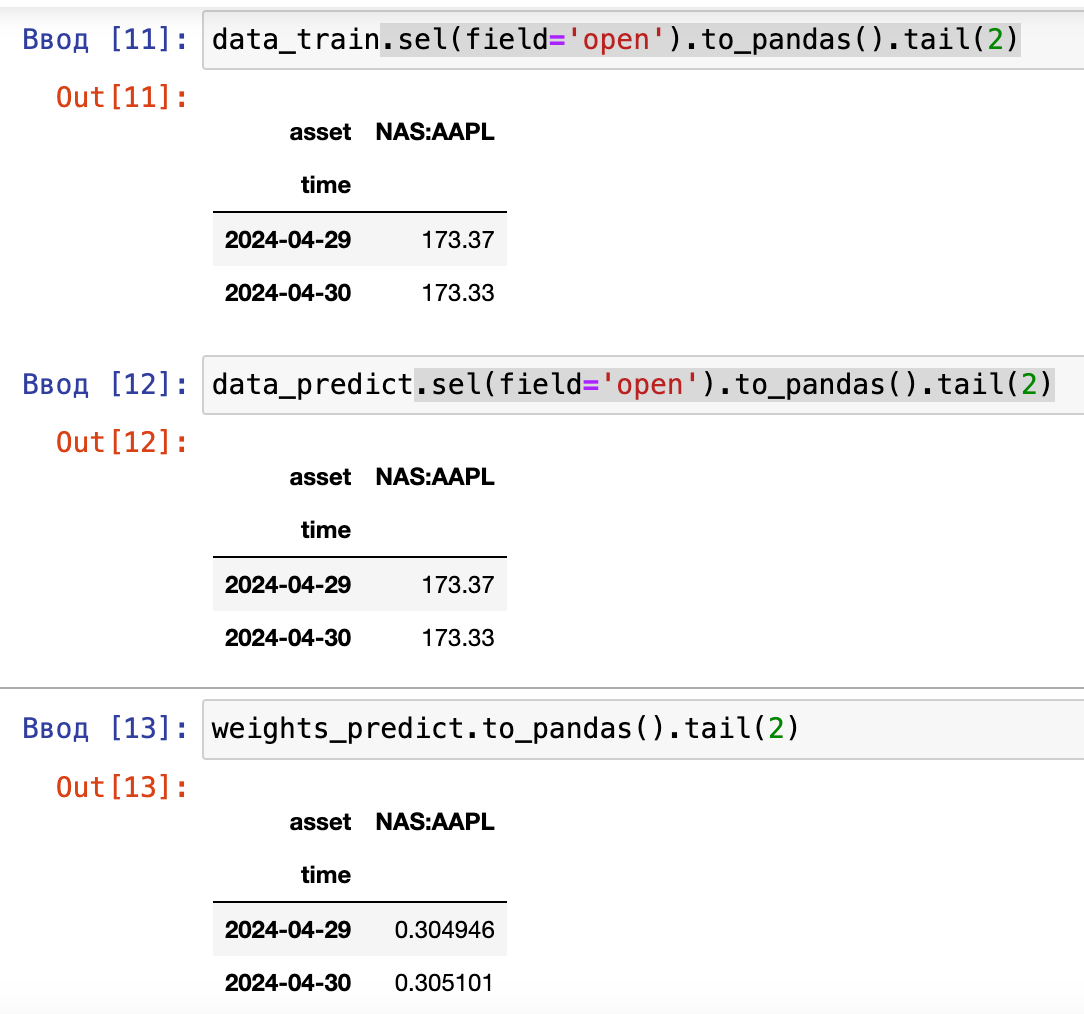
For the last available date in this data, there are no target classes.In each iteration, the backtester operates with the latest forecast. Although the entire series is forecasted, only the last value without an available target class is relevant.
This can be verified by running the function in a single-pass mode and examining the final forecast.
I assume this is done in such a way that the strategy can be run in both single-pass and multi-pass modes.
I became curious, so I will additionally verify what I have written to you.
-
Thank you for your prompt reply. The model is trained correctly, by shifting the label/target column, but if you use the predictions (for the training set timestamps) as the weights for those timestamps, they use information that would not be available in reality.
Because the training set contains data up to the latest timestamps for the slice, while any weight should be derived by looking exclusively at previous timestamps data.
However, I do not know the details of how the qnbt.backtest_ml function does slice the data, but if it uses the weights as they are returned from the predict(models, data) function, then they might be forward-looking. I will look at the single-pass version , that may be different. -
This post is deleted! -
@black-magmar You are correct, but this kind of forward-looking is always present when you have all the data at your disposal. The important point is that there is no forward-looking in the live results, and that should not happen as the prediction will be done for a day for which data are not yet available.
-
This post is deleted! -
This post is deleted! -
Thanks for bringing this up. I had a similar question when looking through the example. From what I understand, it can seem forward-looking at first because of how the data is prepared and the model is trained. The important part is whether the prediction at each point is based only on information that would have been available at that time. If that's the case, then it may not be true look-ahead bias, just a backtesting implementation detail. That said, it's definitely worth double-checking because data leakage in machine learning strategies can be surprisingly easy to miss and can make results look much better than they would be in live trading.