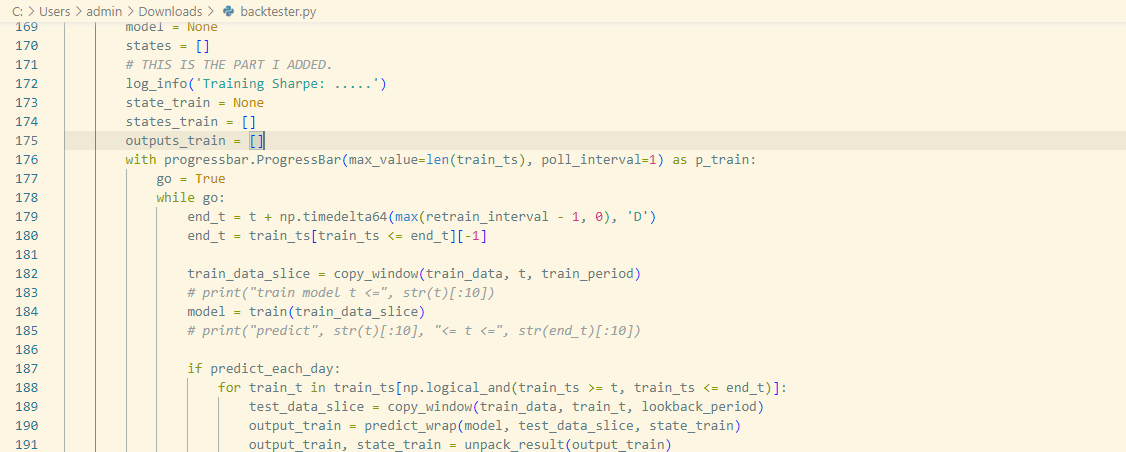
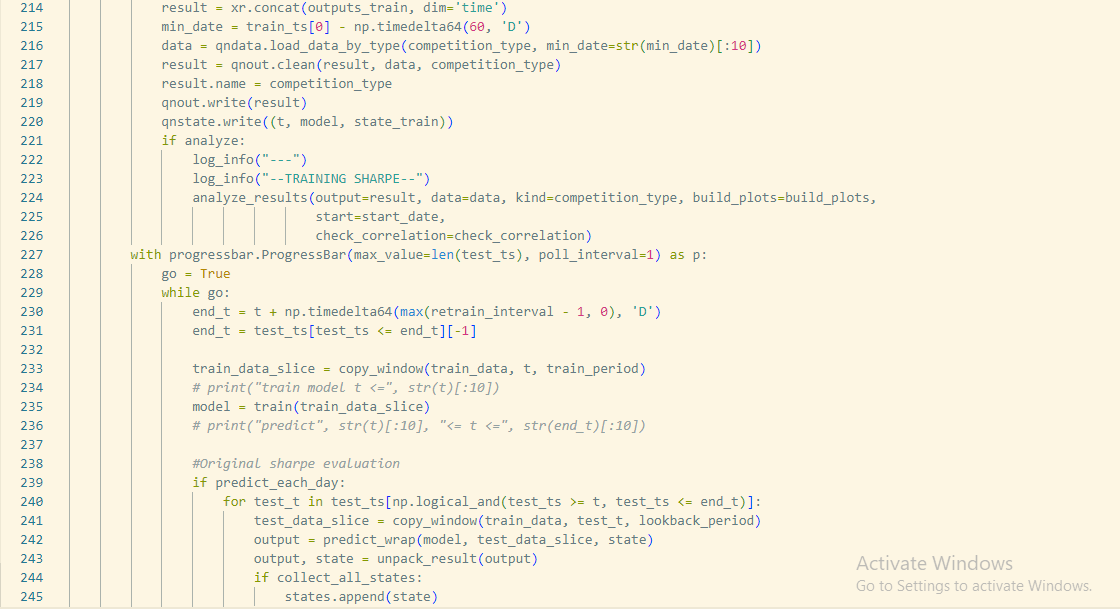
My DL models are filtered by Calculation time exceed.
I have tested it on Google Colab, and the time for it to run qnt.backtest (the last cell) is about 2-3 minutes (without considering some kind of pip install pandas, qnt libraries API).
(Other cells take 0s to run).
Whereas the time for futures is up to 10 minutes.
My submission is made as follows : Click Jupyter, replace "strategy.ipynb" with my "strategy.ipynb" (delete three first cells of installing pandas, qnt libraries ... as suggested), add a new cell in "init.ipynb" : pip install torch.
Can you figure out the root of the problem and how to tackle it ? (you can use LSTM example which is analogous to my model).
@vyacheslav_b