Printing training performance of neural network models
-
I am starting with a LSTM example model (In the example section). I want to print the Sharpe of the model on the training set to compare its Sharpe on test set (which is printed by default). To do that, I am editting the backtester.py file (specifically backtest_ml function) (You can check I added line 172-226 in the editted file for printing the Sharpe of the model on training set in the backtester.py file attached with this post).
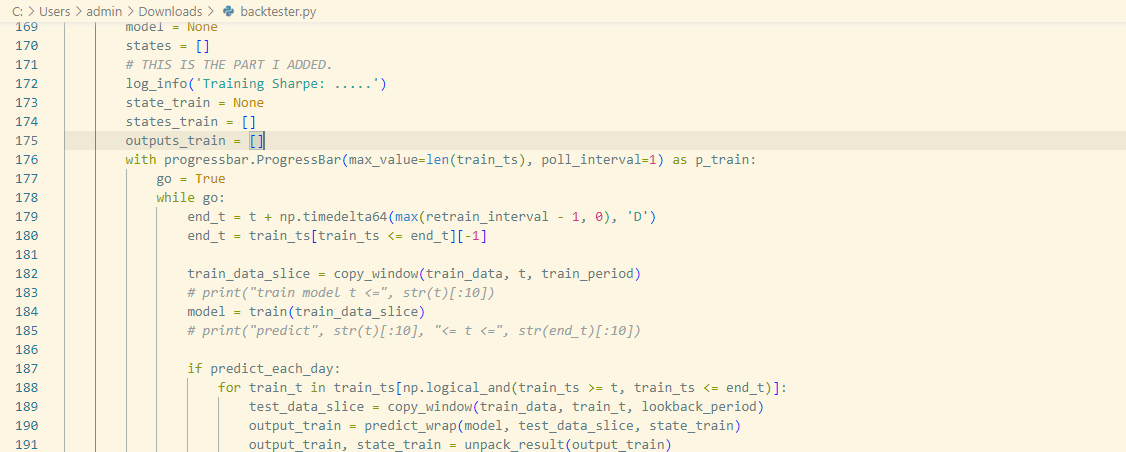

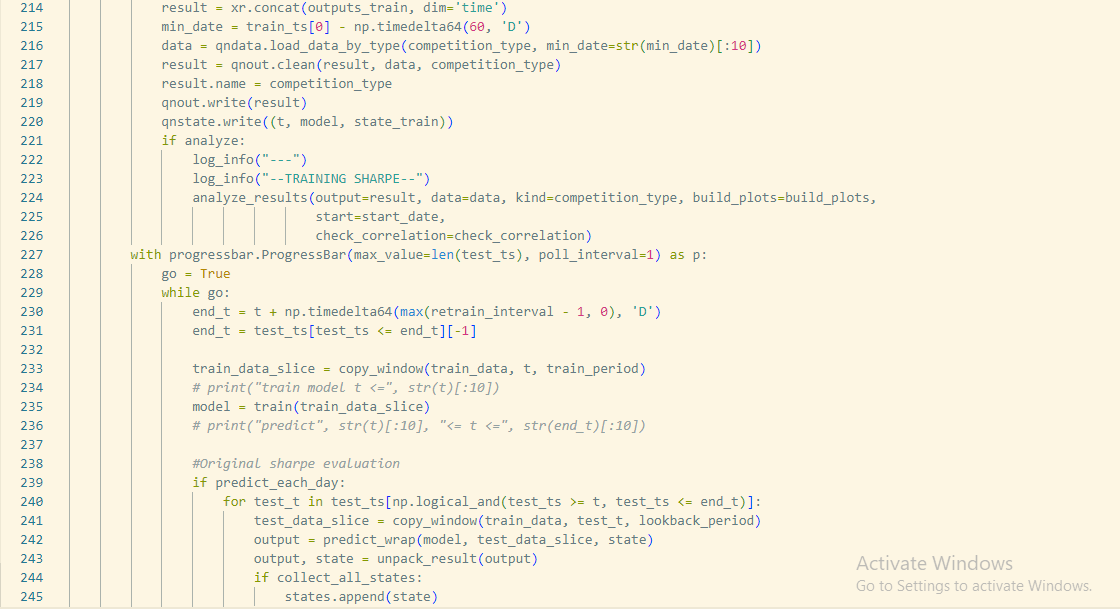
But I got an unexpected result that I think I was doing st wrong : Sharpe of the training is 0.89 and Sharpe of the test set is -0.04; whereas if there was nothing changed in the backtester.py file , the Sharpe by default printed is 0.89.
-
@multi_byte-wildebeest Hello. I think this example of using LSTM will help you
import xarray as xr # xarray for data manipulation import qnt.data as qndata # functions for loading data import qnt.backtester as qnbt # built-in backtester import qnt.ta as qnta # technical analysis library import numpy as np import pandas as pd import torch from torch import nn, optim import random asset_name_all = ['NAS:AAPL'] class LSTM(nn.Module): """ Class to define our LSTM network. """ def __init__(self, input_dim=3, hidden_layers=64): super(LSTM, self).__init__() self.hidden_layers = hidden_layers self.lstm1 = nn.LSTMCell(input_dim, self.hidden_layers) self.lstm2 = nn.LSTMCell(self.hidden_layers, self.hidden_layers) self.linear = nn.Linear(self.hidden_layers, 1) def forward(self, y): outputs = [] n_samples = y.size(0) h_t = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32) c_t = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32) h_t2 = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32) c_t2 = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32) for time_step in range(y.size(1)): x_t = y[:, time_step, :] # Ensure x_t is [batch, input_dim] h_t, c_t = self.lstm1(x_t, (h_t, c_t)) h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2)) output = self.linear(h_t2) outputs.append(output.unsqueeze(1)) outputs = torch.cat(outputs, dim=1).squeeze(-1) return outputs def get_model(): def set_seed(seed_value=42): """Set seed for reproducibility.""" random.seed(seed_value) np.random.seed(seed_value) torch.manual_seed(seed_value) torch.cuda.manual_seed(seed_value) torch.cuda.manual_seed_all(seed_value) # if you are using multi-GPU. torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False set_seed(42) model = LSTM(input_dim=3) return model def get_features(data): close_price = data.sel(field="close").ffill('time').bfill('time').fillna(1) open_price = data.sel(field="open").ffill('time').bfill('time').fillna(1) high_price = data.sel(field="high").ffill('time').bfill('time').fillna(1) log_close = np.log(close_price) log_open = np.log(open_price) features = xr.concat([log_close, log_open, high_price], "feature") return features def get_target_classes(data): price_current = data.sel(field='open') price_future = qnta.shift(price_current, -1) class_positive = 1 # prices goes up class_negative = 0 # price goes down target_price_up = xr.where(price_future > price_current, class_positive, class_negative) return target_price_up def load_data(period): return qndata.stocks.load_ndx_data(tail=period, assets=asset_name_all) def train_model(data): features_all = get_features(data) target_all = get_target_classes(data) models = dict() for asset_name in asset_name_all: model = get_model() target_cur = target_all.sel(asset=asset_name).dropna('time', 'any') features_cur = features_all.sel(asset=asset_name).dropna('time', 'any') target_for_learn_df, feature_for_learn_df = xr.align(target_cur, features_cur, join='inner') criterion = nn.MSELoss() optimiser = optim.LBFGS(model.parameters(), lr=0.08) epochs = 1 for i in range(epochs): def closure(): optimiser.zero_grad() feature_data = feature_for_learn_df.transpose('time', 'feature').values in_ = torch.tensor(feature_data, dtype=torch.float32).unsqueeze(0) out = model(in_) target = torch.zeros(1, len(target_for_learn_df.values)) target[0, :] = torch.tensor(np.array(target_for_learn_df.values)) loss = criterion(out, target) loss.backward() return loss optimiser.step(closure) models[asset_name] = model return models def predict(models, data): weights = xr.zeros_like(data.sel(field='close')) for asset_name in asset_name_all: features_all = get_features(data) features_cur = features_all.sel(asset=asset_name).dropna('time', 'any') if len(features_cur.time) < 1: continue feature_data = features_cur.transpose('time', 'feature').values in_ = torch.tensor(feature_data, dtype=torch.float32).unsqueeze(0) out = models[asset_name](in_) prediction = out.detach()[0] weights.loc[dict(asset=asset_name, time=features_cur.time.values)] = prediction return weights weights = qnbt.backtest_ml( load_data=load_data, train=train_model, predict=predict, train_period=100, retrain_interval=360, retrain_interval_after_submit=1, predict_each_day=False, competition_type='stocks_nasdaq100', lookback_period=155, start_date='2024-01-01', build_plots=True )To get the result on the training set, it is enough to call the predict function for a range of dates.
import qnt.data as qndata import qnt.stats as qns import qnt.graph as qngraph def print_stats(data, weights): stats = qns.calc_stat(data, weights) display(stats.to_pandas().tail()) performance = stats.to_pandas()["equity"] qngraph.make_plot_filled(performance.index, performance, name="PnL (Equity)", type="log") data = qndata.stocks.load_ndx_data(min_date="2023-07-20", assets=asset_name_all) # print_stats(data, weights.sel(time=slice("2024-01-01", None))) models = train_model(data.sel(time=slice("2023-09-25", "2024-01-02"))) weights_slice = predict(models, data.sel(time=slice("2023-09-25", "2024-01-02"))) print_stats(data, weights_slice.sel(time=slice("2023-09-25", "2024-01-02")))I tried increasing the number of epochs and the result got better
-
@vyacheslav_b Thank you for your support. Can you get me an estimation of how big/ much time should our model be ? I run it over 20 years data, some models take 4 or 10 minutes, some take 30s -1 minute (all have Sharpe > 1.0). Can I know the highest Sharpe you achieve through these deep learning models ?
-
@multi_byte-wildebeest Hello. I don't use machine learning models in trading.