@vyacheslav_b Thank you for your response
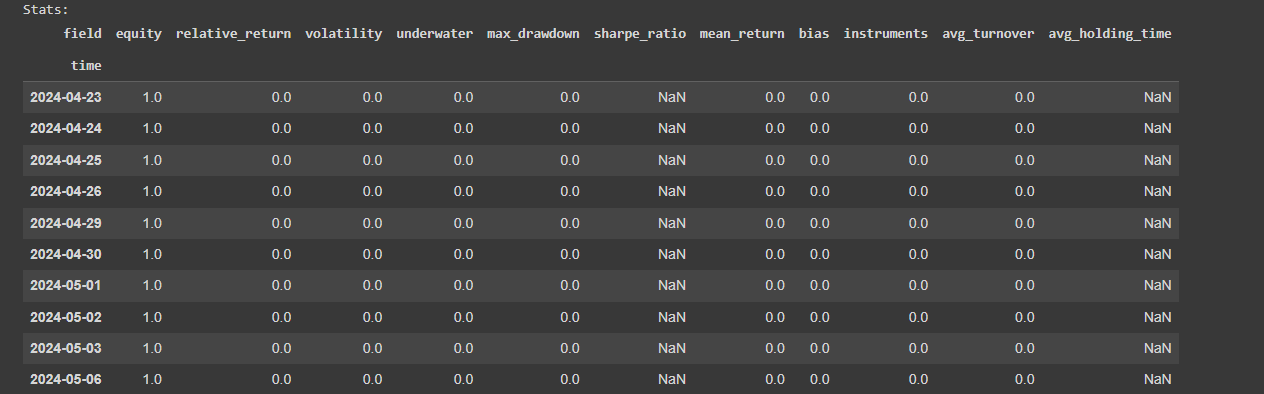
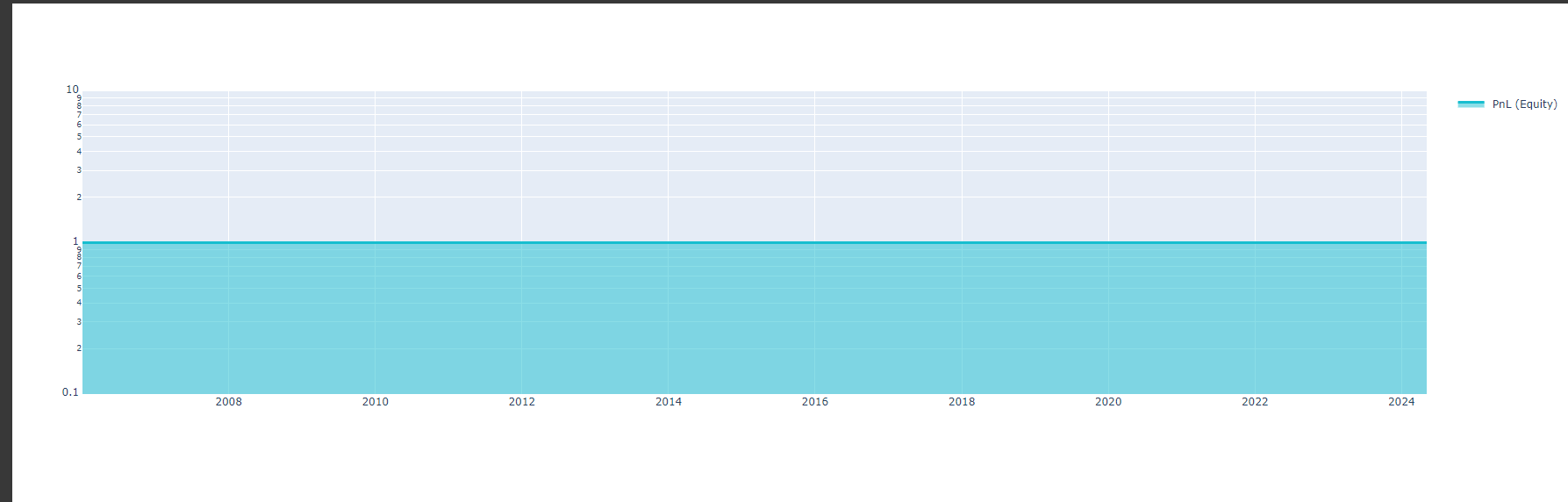
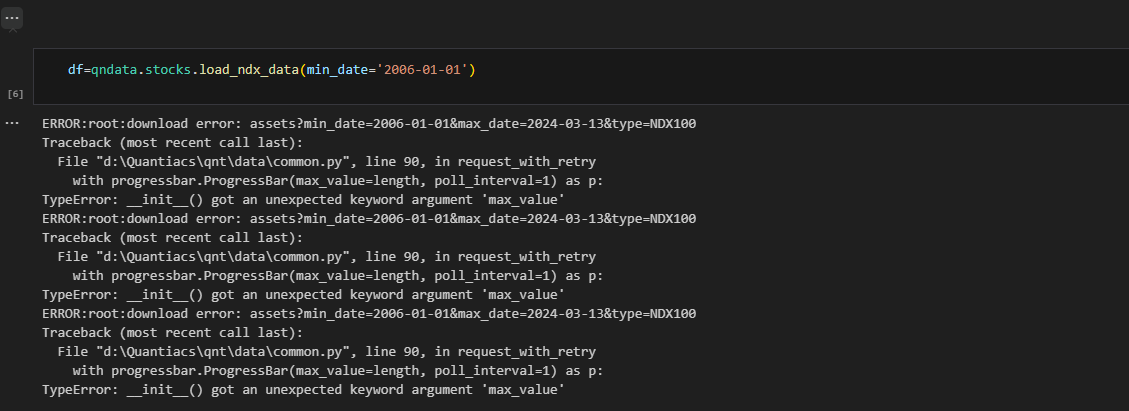
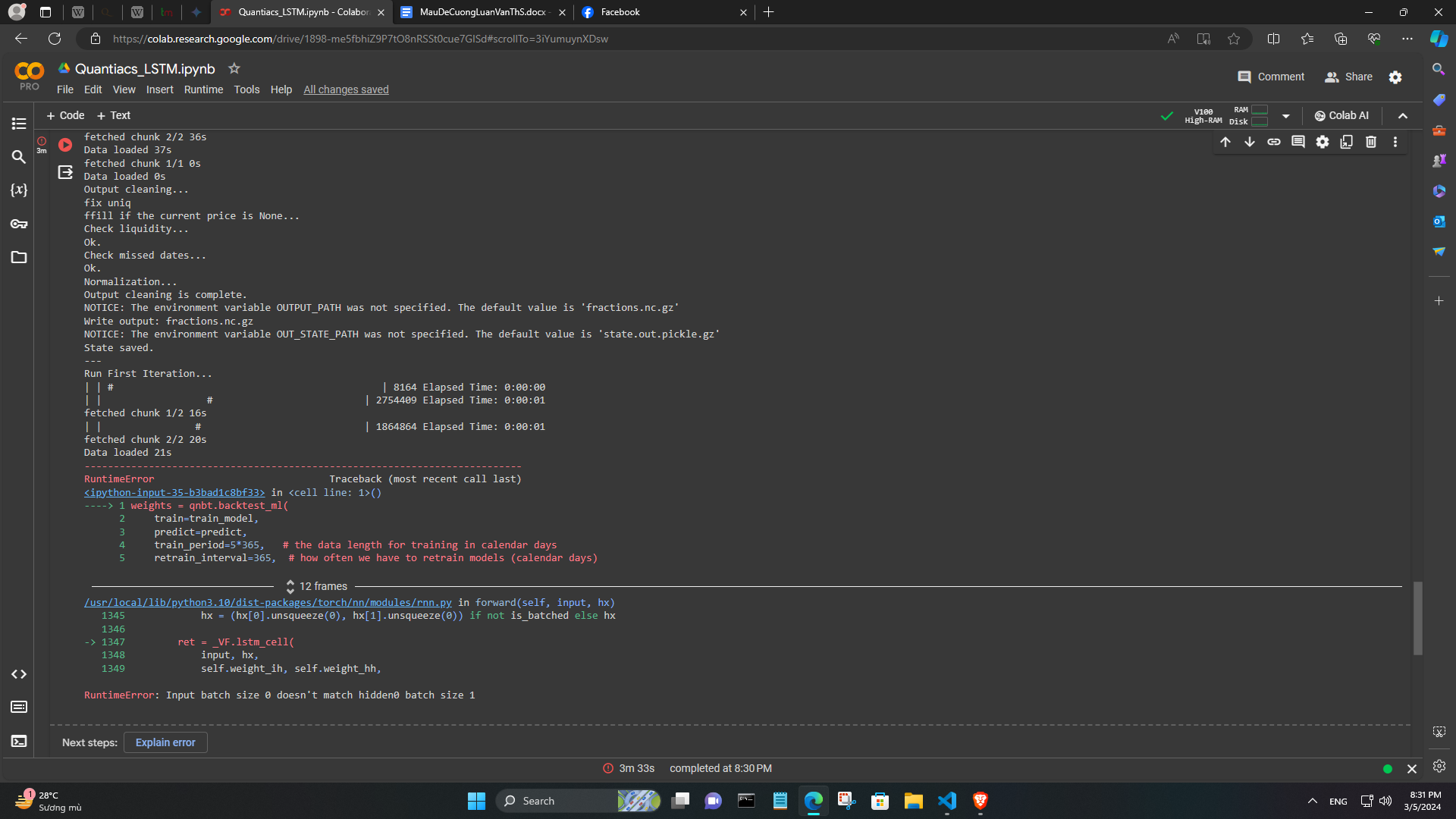
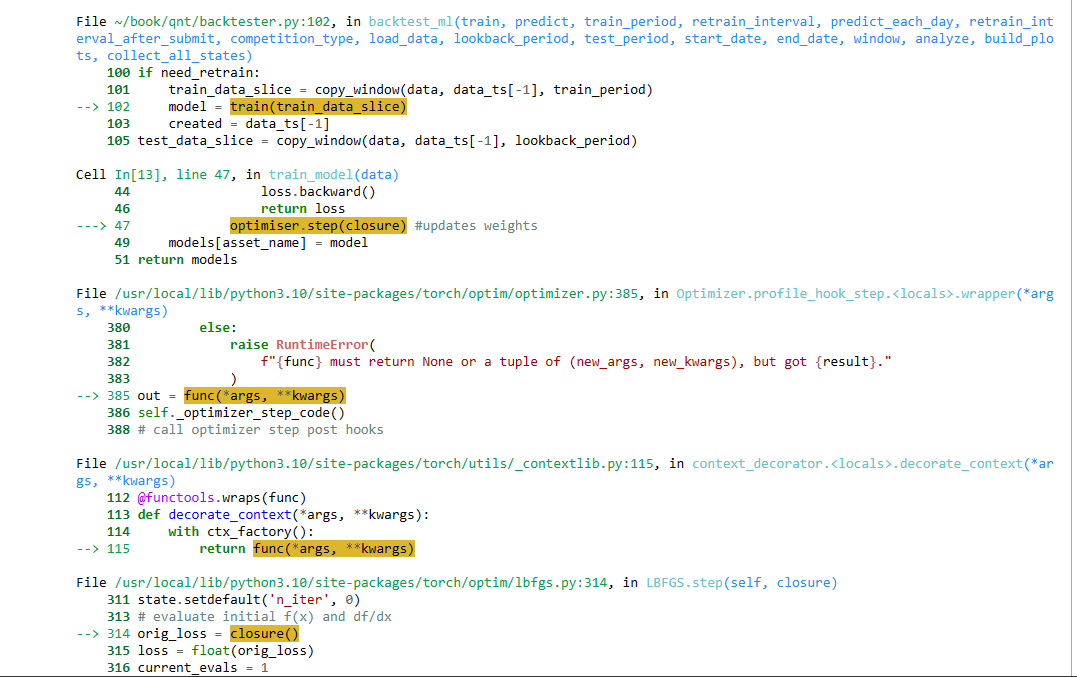
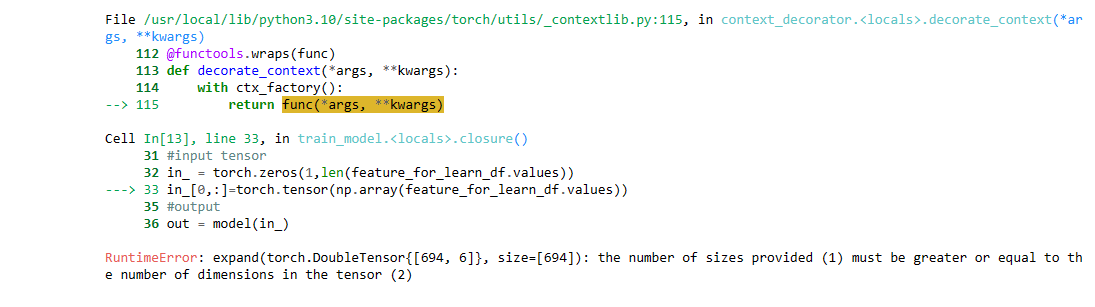
Here is the code I used from your example. I added some other features (eg: trend = qnta.roc(qnta.lwma(data.sel(field='close'), 40), 1),...) and noticed that after passing ml_backtest, every indexes are all nan. Pnl is a straight line. I have tried changing many other features but the result is still the same, all indicators are nan
import xarray as xr
import qnt.data as qndata
import qnt.backtester as qnbt
import qnt.ta as qnta
import qnt.stats as qns
import qnt.graph as qngraph
import qnt.output as qnout
import numpy as np
import pandas as pd
import torch
from torch import nn, optim
import random
asset_name_all = ['NAS:AAPL', 'NAS:GOOGL']
lookback_period = 155
train_period = 100
class LSTM(nn.Module):
"""
Class to define our LSTM network.
"""
def __init__(self, input_dim=3, hidden_layers=64):
super(LSTM, self).__init__()
self.hidden_layers = hidden_layers
self.lstm1 = nn.LSTMCell(input_dim, self.hidden_layers)
self.lstm2 = nn.LSTMCell(self.hidden_layers, self.hidden_layers)
self.linear = nn.Linear(self.hidden_layers, 1)
def forward(self, y):
outputs = []
n_samples = y.size(0)
h_t = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32)
c_t = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32)
h_t2 = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32)
c_t2 = torch.zeros(n_samples, self.hidden_layers, dtype=torch.float32)
for time_step in range(y.size(1)):
x_t = y[:, time_step, :] # Ensure x_t is [batch, input_dim]
h_t, c_t = self.lstm1(x_t, (h_t, c_t))
h_t2, c_t2 = self.lstm2(h_t, (h_t2, c_t2))
output = self.linear(h_t2)
outputs.append(output.unsqueeze(1))
outputs = torch.cat(outputs, dim=1).squeeze(-1)
return outputs
def get_model():
def set_seed(seed_value=42):
"""Set seed for reproducibility."""
random.seed(seed_value)
np.random.seed(seed_value)
torch.manual_seed(seed_value)
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value) # if you are using multi-GPU.
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)
model = LSTM(input_dim=3)
return model
def get_features(data):
close_price = data.sel(field="close").ffill('time').bfill('time').fillna(1)
open_price = data.sel(field="open").ffill('time').bfill('time').fillna(1)
high_price = data.sel(field="high").ffill('time').bfill('time').fillna(1)
log_close = np.log(close_price)
log_open = np.log(open_price)
trend = qnta.roc(qnta.lwma(close_price ), 40), 1)
features = xr.concat([log_close, log_open, high_price, trend], "feature")
return features
def get_target_classes(data):
price_current = data.sel(field='open')
price_future = qnta.shift(price_current, -1)
class_positive = 1 # prices goes up
class_negative = 0 # price goes down
target_price_up = xr.where(price_future > price_current, class_positive, class_negative)
return target_price_up
def load_data(period):
return qndata.stocks.load_ndx_data(tail=period, assets=asset_name_all)
def train_model(data):
features_all = get_features(data)
target_all = get_target_classes(data)
models = dict()
for asset_name in asset_name_all:
model = get_model()
target_cur = target_all.sel(asset=asset_name).dropna('time', 'any')
features_cur = features_all.sel(asset=asset_name).dropna('time', 'any')
target_for_learn_df, feature_for_learn_df = xr.align(target_cur, features_cur, join='inner')
criterion = nn.MSELoss()
optimiser = optim.LBFGS(model.parameters(), lr=0.08)
epochs = 1
for i in range(epochs):
def closure():
optimiser.zero_grad()
feature_data = feature_for_learn_df.transpose('time', 'feature').values
in_ = torch.tensor(feature_data, dtype=torch.float32).unsqueeze(0)
out = model(in_)
target = torch.zeros(1, len(target_for_learn_df.values))
target[0, :] = torch.tensor(np.array(target_for_learn_df.values))
loss = criterion(out, target)
loss.backward()
return loss
optimiser.step(closure)
models[asset_name] = model
return models
def predict(models, data, state):
last_time = data.time.values[-1]
data_last = data.sel(time=slice(last_time, None))
weights = xr.zeros_like(data_last.sel(field='close'))
for asset_name in asset_name_all:
features_all = get_features(data_last)
features_cur = features_all.sel(asset=asset_name).dropna('time', 'any')
if len(features_cur.time) < 1:
continue
feature_data = features_cur.transpose('time', 'feature').values
in_ = torch.tensor(feature_data, dtype=torch.float32).unsqueeze(0)
out = models[asset_name](in_)
prediction = out.detach()[0]
weights.loc[dict(asset=asset_name, time=features_cur.time.values)] = prediction
weights = weights * data_last.sel(field="is_liquid")
# state may be null, so define a default value
if state is None:
default = xr.zeros_like(data_last.sel(field='close')).isel(time=-1)
state = {
"previus_weights": default,
}
previus_weights = state['previus_weights']
# align the arrays to prevent problems in case the asset list changes
previus_weights, weights = xr.align(previus_weights, weights, join='right')
weights_avg = (previus_weights + weights) / 2
next_state = {
"previus_weights": weights_avg.isel(time=-1),
}
# print(last_time)
# print("previus_weights")
# print(previus_weights)
# print(weights)
# print("weights_avg")
# print(weights_avg.isel(time=-1))
return weights_avg, next_state
weights = qnbt.backtest_ml(
load_data=load_data,
train=train_model,
predict=predict,
train_period=train_period,
retrain_interval=360,
retrain_interval_after_submit=1,
predict_each_day=True,
competition_type='stocks_nasdaq100',
lookback_period=lookback_period,
start_date='2006-01-01',
build_plots=True
)